
.webp)
Subscribe to Our Newsletter
Read the latest in the world of AI, data center, and edge innovation.

The rise of AI is exposing a widening gap between what modern data centers were designed to do and what AI workloads now demand. Boards and executive teams expect faster time-to-value from AI investments. Quietly, the infrastructure has become the bottleneck.
At AI Infrastructure Field Day 4 (AIIFD4), the Cisco Data Center Networking team addressed this gap head-on. Cisco made it clear they are not walking away from Ethernet. Instead, they are rethinking what Ethernet needs to become to reliably support the unique demands of AI workloads.
AI workloads behave very differently from traditional enterprise applications. Training and large-scale inference generate long-lived, east west, GPU-to-GPU flows that are extremely sensitive to latency, jitter, and packet loss. Even minor congestion can cascade into stalled jobs, underutilized GPUs, and missed business deadlines.
During the session, a critical business consequence became obvious: time-to-first-token (TTFT) now matters as much as raw performance. Delays caused by network misconfiguration, troubleshooting blind spots, or prolonged deployment cycles directly erode the return on multimillion dollar GPU investments. In many cases, organizations lose months of effective depreciation time before AI clusters deliver meaningful value.
In other words, long TTFT times mean expensive GPUs are sitting idle while the teams troubleshoot the network.
This is where the gap emerges. Traditional Ethernet is optimized for best-effort, north-south traffic. It was never designed for sustained, lossless, ultra-dense GPU communication. At the same time, many enterprises lack the operational appetite to introduce entirely separate fabrics just to support AI.
Surprisingly, one theme that came through clearly was that plain Ethernet is not enough for modern AI clusters.
Standard Ethernet assumes packet loss is acceptable and recoverable. AI training does not. When one GPU waits on another due to congestion or dropped packets, the entire job slows down. No amount of compute spend can compensate for unpredictable network behavior.
Beyond performance, there is an operational issue. AI environments introduce unprecedented complexity across compute, storage, optics, and networking. Without deep visibility, network teams are often blamed first. But they usually don’t have the telemetry needed to prove where problems actually originate.
It’s hard to understand the challenge when you look at the complexity of a “small” 96 GPU network topology:
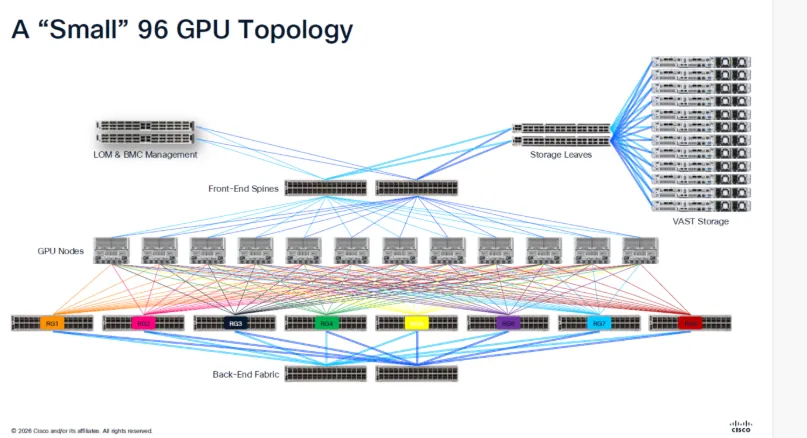
This is an executive level risk. AI failure modes are no longer isolated to IT, they impact product timelines, research velocity, and competitive advantage.
InfiniBand has long been the gold standard for HPC and AI training. It delivers native losslessness and extremely low latency, and it performs exceptionally well in controlled environments.
However, Cisco drew a clear contrast at AIIFD4. While InfiniBand works technically, it introduces business and operational challenges for enterprises:
It creates a separate fabric with specialized tooling and skills.
It limits multitenancy and segmentation, which are essential for shared enterprise AI platforms.
It offers limited end-to-end observability, particularly outside the fabric itself.
It complicates convergence with storage and front-end networks.
InfiniBand excels as a purpose-built backend fabric. But most enterprises aren’t building isolated AI factories. They are trying to operationalize AI alongside everything else.
Cisco’s AIIFD4 appearance was not about replacing Ethernet, it was about evolving it.
Their approach combines Ethernet’s universality with AI-specific enhancements that deliver predictability and control. This transforms Ethernet from a best effort transport into a deterministic system fabric, capable of supporting AI training and inference without introducing separate operational silos.

One of the most important themes from Cisco’s sessions was that security in AI data centers is about insight and control. It can’t be just about isolation.
Cisco’s AI-optimized Ethernet emphasizes:
Logical segmentation using EVPN-VXLAN, enabling strong multitenant isolation
Secure, TLS-based control plane communication in cloud managed environments like Nexus Hyperfabric
Proactive detection of physical layer issues, such as optic degradation, before they impact workloads
Job-level analytics that tie performance anomalies directly to infrastructure causes
The common thread is control: seeing problems early, understanding their impact, and fixing them before GPUs go idle.
This level of visibility simply does not exist in traditional InfiniBand environments. Cisco’s argument is that what you can see, you can secure, and what you cannot see becomes a business risk.
Cisco’s appearance at AIIFD4 reframed the Ethernet versus InfiniBand debate as a business decision, not just a technical one.
For hyperscalers building single purpose AI factories, InfiniBand may remain the right choice. But for enterprises building multiple AI clusters, often incrementally, across teams and use cases, Cisco’s AI optimized Ethernet offers a compelling alternative: one fabric, one operating model, and one security posture.
The takeaway for executives is simple: the question is no longer whether Ethernet can support AI. The question is whether your Ethernet is engineered for determinism, visibility, and AI scale operations.
Cisco’s answer at AIIFD4 was clear. Enterprises don’t need a second fabric to keep up with AI. They need Ethernet that has been deliberately engineered for determinism, visibility, and scale.
Q: What is AI Ethernet?
A: AI Ethernet is Ethernet that has been deliberately engineered for AI workloads, with deterministic performance, lossless behavior, and end-to-end observability to support large GPU clusters at scale.
Q: Why isn’t standard Ethernet sufficient for AI workloads?
A: Standard Ethernet assumes packet loss is acceptable. AI training workloads are tightly synchronized, so even small amounts of loss or congestion can stall jobs and leave expensive GPUs underutilized.
Q: How does deterministic networking improve AI performance?
A: Deterministic networking delivers predictable latency and controlled congestion, which leads to faster job completion, higher GPU utilization, and more reliable AI production timelines.
Q: When does InfiniBand make sense for AI?
A: InfiniBand can be a good fit for hyperscalers or single purpose AI factories. Enterprises running shared, multitenant AI platforms often find its operational complexity and lack of convergence limiting.
Q: Why is observability critical for enterprise AI networking?
A: AI environments span GPUs, NICs, switches, and optics, making issues hard to diagnose without end-to-end visibility. Observability enables faster root cause analysis and reduces the risk of idle GPUs and lost value.
Q: Is AI Ethernet only about performance?
A: No. AI Ethernet also addresses operational simplicity, security, and risk by combining visibility, segmentation, and policy driven control as AI platforms scale. driven control as AI platforms scale.
