
Welcome to
the Forum
Engage innovators and practioners on the edge of technology advancement.






.webp)
Support your Local [Sherrif] Sysadmin
The plot of the 1969 Western calls for James Garner to produce exasperated and amused facial expressions as his character attempts to emigrate to Australia but is frustrated by a lack of funds. The character he portrays, Jason McCollough, is stuck in a nineteenth century frontier town put on the map due to an accidental discovery of gold. Because the cost of living in town inflates hourly and the pay is good, McCollough, a brilliant gunslinger, reluctantly accepts the job as the local sheriff.
This also happens to be a solid description of most IT and sysadmins I’ve worked with over the years. Quick on the draw when it comes to technical challenges, sysadmins are a jack of all trades who can resolve issues with both ingenuity and a refreshing lack of perfectionism when stabilizing a situation. Also: many sysadmins are not in the job they envisioned when they graduated, must work with the equivalent of the town ‘character’, and have gleeful management who are thrilled someone else deals with the local mess of bad horses, bad men and bad decisions.
One challenge for a sysadmin is that like the sheriff, when things are going smoothly, neither of them is front of mind for day-to-day operations. You only notice them when unwelcome changes occur, such as a core software platform provider gets bought out by an aggressive organization operating like a PE who then squeezes the clientele for more juice. As a sysadmin you have no good choices: costs might suddenly triple, but you built your disaster recovery plan on this technology. You’re “encouraged” to move to new products if you know what's good for you – can you really afford to walk away from the new owner who decided to weaponize their newly held asset against you, their customer?
Even the low-grade annoyances can flare up out of the blue. Accepting a service providers’ half-hearted developer experiences, inscrutable services catalogs, or byzantine documentation because they offer stability in reliability, identity and service boundaries seems like reasonable tradeoff. Until the service provider starts surprising you with issues in authorization checks and access controls across your VMs, then responds to legitimate customer sysadmin concerns with a statement: “No one has really found that exploit in a real world situation.”
Notice that even mature, decades-old technologies from suppliers who had been stable, if not accommodating, business partners can be a new wrinkle for sysadmins. A new singularity in the form of AI springs new leaks in what had been a relatively steady-state environment. Today, sysadmins have a trifecta of fleet-wide technology changes that are necessary to get the most from AI, bad actors who use AI to launch attacks at a scale human teams can’t match, and a core technology that no one has yet mastered the art of setting or meeting budget projections for. A recent KPMG report states that nearly 1/3 of corporate leaders are finding it difficult to understand the operating costs, much less control them when it comes to AI implemented at enterprise scale. It’s not just financial operations either: there are new potential legal exposures related to copyright ownership, new supplier contract terms and/or unintended regulatory missteps.
For the AI-plagued sysadmin, here are a few shortlist areas for your triage efforts.
First, protect the areas where the entire company could be put at risk:
- For product development, consider a private AI implementation or open weights model, small language models or industry-specific models you fine tune. This can help ensure your use of AI in product development isn’t a two-way channel that trains your supplier’s AI on how you develop your products as the basis for future competitors. This is especially important if your product happens to be software and is currently protected through copyright.
- Ensure that any new tools or technology suppliers can meet your insurability requirements through contract negotiations or vendor selection processes
- Employ AI for threat detection including fraud detection while being very deliberate and prescriptive about where AI is allowed to take action to remediate.
Next, use “multi-cloud” principles to ensure company operations can run independent of specific models to avoid vendor API lock-in and build in finOps modeling to anticipate budget “tops and tails."
No CFO has ever been excited to hear sysadmins tell them “I have no idea what budget I need, or whether I can hit the budget within 5% of my estimates”. Like cloud services as they matured, AI tooling prices have experienced wild swings in the last three years, and model retirement has already caused headaches for what were once stable enterprise workflows.
Finally, look for real-time operational governance capabilities in your AI solutions.
The regulatory landscape for AI is broad, varies greatly between states and nations, and can carry significant penalties for missteps. In the old west, the town charter and the town council were necessary but not sufficient to tackle the opportunities and challenges that came from a sudden influx of gold prospectors. Similarly, AI governance committees are necessary, but not sufficient in a playing field that changes at the speed of compute.
In the end, the role of the sysadmin hasn’t changed nearly as much as the environment around them. Like the reluctant sheriff, they step in not because the job is easy or glamorous, but because someone has to keep order when complexity and chaos collide. As AI reshapes the frontier yet again, the tools may evolve and the stakes may rise, but the mission remains the same: protect the town, steady the systems, and make sure everyone gets through the day without noticing just how close things came to going off the rails. So, this Sysadmin Day, remember—the quiet stability you rely on is no accident; it’s the work of someone who’s always on watch, even when you don’t see them.

Qualcomm on Designing AI Inference for Efficiency First
Leading up to the AI Infra Summit in September, TechArena has spent the summer talking with the companies building AI infrastructure, from hyperscalers to storage, memory and networking, through to the power, cooling, and silicon that hold these systems together.
In our latest Five Fast Facts Q&A, we chatted with Tony Pialis, EVP and GM of Data Center at Qualcomm. He explains what changes when a company that grew up counting every milliwatt in mobile brings that discipline to inference. We discussed the memory wall, why data movement now costs more than compute, and what it takes to sell a rack instead of a chip. Here's what we learned.
Q1: Qualcomm comes to the data center from mobile, where every milliwatt counts. What does designing for energy efficiency first let you do in an inference rack that a chip built for the data center might miss?
A: Qualcomm’s perspective is different because we grew up solving compute problems under severe power constraints. In mobile, every milliwatt matters because battery life, thermals, and form factor are critical. That mindset translates directly to our AI inference solutions, since the real challenge in modern data centers is no longer peak compute, but delivering the most AI work within a constrained power and investment envelope.
Designing for efficiency first enables us to optimize the entire rack around cost-per-token and power efficiency rather than chasing benchmark peaks. Qualcomm Dragonfly combines specialized CPUs, AI accelerators, memory innovation through High Bandwidth Compute (HBC), and advanced connectivity in a disaggregated architecture designed specifically for inference. Our multi-generation roadmap is focused on maximizing performance per watt, improving token economics, and lowering total cost of ownership at scale.
Q2: What do you see as the real limit on AI inference today, and what did designing around it lead you to build differently?
A: The biggest constraint in AI inference isn’t raw compute anymore—it’s moving data efficiently. Model sizes are growing far faster than memory bandwidth and capacity, creating what the industry increasingly describes as the memory wall. Qualcomm believes that simply adding more compute does not solve the problem if memory becomes the bottleneck.
That realization led us to develop HBC, a near-memory computing architecture that brings compute and memory much closer together. Instead of shuttling massive amounts of data back and forth, HBC performs more processing near memory, reducing movement, lowering power consumption, improving effective memory bandwidth, and lowering overall system costs. HBC is poised to deliver significantly higher bandwidth-per-watt and capacity-per-watt compared with traditional approaches. The outcome is infrastructure designed specifically for modern AI inference workloads where efficiency, scalability, and predictable economics matter as much as performance.
Q3:. Qualcomm built its name in silicon, and Dragonfly now sells the whole rack as one liquid-cooled product. What did moving from selling chips to delivering a full rack force you to learn, and what still trips operators up in that shift?
A: I would characterize Dragonfly as a portfolio of rack-scale platforms rather than a single liquid-cooled product. Depending on the deployment, Dragonfly systems can support air or direct-liquid cooling. What is important is that customers increasingly evaluate AI infrastructure at the system level—not as isolated chips.
AI infrastructure is increasingly a systems problem rather than a chip problem. Customers no longer evaluate silicon in isolation—they care about rack-level performance, power consumption, networking, software orchestration, cooling, and overall cost of ownership. Qualcomm Dragonfly reflects that reality by bringing CPUs, AI accelerators, memory architecture, connectivity, software, and custom silicon together into a unified data center platform.
Optimizing one component is not enough. The infrastructure must work as an integrated system. One persistent challenge for operators is balancing compute, memory, networking, and power at scale. Bottlenecks often emerge not from lack of processing power but from inefficient data movement, infrastructure complexity, or underutilized resources. Our approach is to simplify this by delivering a rack-scale platform designed around inference efficiency, open software, disaggregated compute that help customers scale economically as agentic AI dramatically increases token demand.
Q4: Qualcomm has pulled its CPU, accelerators, connectivity DSPs, and management software together partly through acquisition and partnership. What has to be true for those pieces to run as one machine rather than a bundle, and where are the seams still real?
A: To operate as a single platform, every layer must be designed around common system objectives: performance, efficiency, openness, and scale. Qualcomm’s strategy combines CPUs, AI accelerators, connectivity technologies, custom silicon, orchestration software, and developer tools into a unified architecture optimized for AI inference. The software layer is especially important because it coordinates workloads across heterogeneous compute resources and abstracts complexity from developers and operators.
At the same time, we believe openness matters. AI infrastructure is becoming increasingly heterogeneous, with CPUs, GPUs, XPUs, and specialized accelerators coexisting. The real challenge is enabling those components to work together efficiently. The seams that remain are often industry-wide—not unique to Qualcomm—including interoperability across different hardware ecosystems, software stacks, and deployment environments. Our goal is to minimize those seams through open standards and unified software rather than proprietary lock-in.
Q5: Inference increasingly gets bought on cost per token, not peak specs. From where Qualcomm sits, what most decides whether an operator can hold a predictable cost per token, and how much of that is set at the memory and rack level?
A: We believe the industry is undergoing a fundamental shift from measuring AI infrastructure by peak FLOPS to measuring it by tokens per watt and ultimately cost per token. As agentic AI drives massive growth in inference requests, economics become the defining factor. Operators need infrastructure that can deliver consistent throughput while managing power, cooling, and hardware utilization efficiently.
Memory architecture plays a central role because data movement increasingly consumes more energy than computation itself. That’s why Qualcomm invested in High Bandwidth Compute, which is designed to reduce energy consumed moving data, improve effective bandwidth, and lower total cost of ownership. But cost per token is ultimately determined at the rack level as well. Compute, memory, software orchestration, networking, and cooling must be optimized together. Qualcomm Dragonfly was built around that systems view, using a disaggregated rack-scale architecture to maximize utilization and efficiency. In our view, the winners in AI inference will be those who can consistently deliver the best performance-per-watt, performance-per-dollar, and long-term economics—not simply the highest headline specifications.
img.jpg)
Nebius on the Full-System Thinking Behind AI Infrastructure
The world tends to measure artificial intelligence (AI) progress in two units: the number of graphics processing units (GPUs) deployed and the megawatts they consume. Yet the people who actually build these systems know that the GPU count is only one part of a much larger engineering effort. Power delivery, cooling, networking, and storage all have to come together before a single accelerator does useful work, and the discipline of fitting those pieces together is becoming one of the most consequential roles in the data center.
On a recent TechArena Data Insights episode, Solidigm’s Jeneice Wnorowski and I explored that hidden layer of the AI buildout with Hitesh Kumar, a GPU cluster architect at Nebius, an AI cloud company that has been drawing attention across the neocloud landscape. Our conversation moved from custom hardware and proprietary software to power heavy AI workloads.
The System Beyond the GPU
Hitesh described his role as starting once a site has been selected and power secured, and ending when responsibility passes to the logistics and deployment teams. That gap, he explained, is where his team plans clusters, maps them onto floor plans, and decides what connects to what. The work is deliberately broad, and much of it has little to do with the accelerators themselves.
“My job as a GPU cluster architect focuses on a lot of things that aren’t GPUs,” he said. Power and cooling are a major part of the discussion, and so are networking, storage, and the management plane that orchestrates everything. In fact, it’s only after that supporting infrastructure is planned that the headline GPU count comes back into the picture.
Storage and Interconnects Move to the Foreground
Storage has always mattered for training AI models, as data must reach the GPUs fast enough to avoid stalls. Hitesh noted that inference, or running those models in production, is now creating fresh demand beyond that baseline. With a large language model (LLM) chat bot for example, the full state of a long conversation increasingly needs to move off the GPU, and sometimes off the server entirely, with storage acting as an intermediate tier between what a GPU holds close and what it will need soon.
Interconnects are evolving in a similar trajectory. Hitesh traced a path from today’s pluggable optics that enable a connection to one to two cables toward denser designs with tens of ports per unit, and eventually toward co-packaged optics that place optical engines directly in the server. Each step raises new challenges in cooling, cabling, and supply chain readiness that operators must manage alongside the mature technology they rely on today.
The Hidden Costs of Scale
Adding GPUs sounds simple, but Hitesh pointed to two realities that catch teams off guard. The first is component failure. Citing Meta’s published study of a 16,000 GPU cluster, he noted that Meta’s team experienced a failure every three hours on average. At that rate, software must become genuinely fault tolerant, and operations, spares, and logistics all have to scale to match.
The second unanticipated challenge is power behavior. Hitesh highlighted the scale of the power that clusters now draw, and he described how a checkpoint pause can drop a rack tens of kilowatts in moments. Swings that large can affect the grid, pushing operators to consider capacitors, batteries, or software mitigations that rarely make the headlines.
Building Smart and Looking Ahead
For organizations early in their AI journey, Hitesh offered valuable guidance. Going from zero to one, he said, “you really don’t want to be thinking about buying your own infrastructure,” given the high startup costs and overhead. Cloud resources make sense first, followed by colocation, and eventually a dedicated site once demand justifies it.
Looking forward, he expects steady efficiency gains, with “every part of your stack” delivering more performance per dollar. The change he finds most interesting is in network topology. He anticipates clusters organized as “lots of small islands of very tightly connected GPUs,” linked by sparser scale-out and scale-across fabrics. He sees the same fractal pattern emerging across NVIDIA rack-scale designs, Google’s tensor processing units (TPUs), and Huawei’s accelerators alike.
The TechArena Take
Hitesh’s perspective provides a useful counterpoint to conversations that reduce AI infrastructure to a single metric. The teams that succeed will treat power, cooling, storage, and networking as first-class design decisions rather than afterthoughts, and will scale their operational maturity in step with their hardware. As models grow and inference proliferates, the competitive advantage will belong to operators who understand the entire system. For decision makers planning their own buildouts, that full-system discipline is no longer optional.
If you want to learn more about Nebius visit https://nebius.com/

How CelLink Brings Flat Power Delivery to the Rack
Leading up to AI Infra Summit this September, we're continuing our conversations with players across the data center stack to learn what AI infrastructure demands and what's being built to meet it. Those talks run from hyperscalers through storage, memory, and networking, out to power, cooling, and rack-scale architecture.
For this installment, I was delighted to catch up with Steve Thorne, chief commercial officer of CelLink. The company spent more than a decade building flat, flexible power circuits for electric vehicles, and it has now brought that form factor to the data center. Its PowerPlane swaps out thick bundles of discrete wires for a single laminated circuit thin enough to route thousands of amps in less space than a cable harness used to fill. Motherboards dock straight to it. And because that same flat layer can align with liquid-cooling manifolds and pull heat off the backside of the board, where vertical power regulators run hottest, Thorne makes the case that power and cooling no longer have to fight for the same cramped space. Here's what I learned.
Q1: CelLink came away from OCP 2025 asserting that the unit of design has moved from the server box to the rack and beyond, with whole racks and pods sold as finished products. What does designing at rack scale change about how power has to be delivered, and what still trips operators up in that shift?
A: Designing at rack scale forces power delivery to be considered as a first-class constraint alongside compute and cooling, rather than an afterthought bolted on at the end. Flat, flexible power delivery infrastructure must now be co-designed across the full rack and pod, rather than being treated as independent subsystems. The old approach of designing subsystems in isolation has caused integration oversights and schedule delays. By coupling flat power delivery with cooling infrastructure from the start, operators can improve current-carrying capacity, reduce energy loss, and avoid the last-minute surprises that still trip up many rack-scale deployments.
Q2: Your PowerPlane delivers thousands of amps through a flat circuit under a millimeter thick, and motherboards dock straight to it instead of being wired one cable at a time. What does taking power delivery flat and into the rack free up, and why does that matter for an AI server?
A: The flat geometry of the CelLink flex harness eliminates the volumetric overhead of round wire bundles, freeing space inside the compute tray for larger compute modules and liquid cooling infrastructure. Silicon vendors also benefit: by routing power interconnects to the underside of the chip, more I/O and fiber optic connections can be placed around the GPU or AI accelerator periphery. Moving the Power Distribution Network (PDN) out of the PCB also enables more thermally-efficient delivery—less energy lost to heat means more power available for compute.
Beyond space, CelLink flex harnesses enable automated system assembly. Their flat, thin profile is far more compatible with robotic pick-and-place equipment than conventional cable bundles, reducing manual labor and improving assembly consistency at scale.
Q3: CelLink contends that efficiency now must span the whole power path, from the grid down to the last centimeters inside the server. Where is the most power and space lost today, and how do higher-voltage delivery and vertical power to the back of the board change that picture?
A: Significant power is lost inside the GPU tray along the conversion chain from 800V down to 50V, 12V or 6V, and finally sub-1V at the silicon. At each step down in voltage, current rises sharply, and I²R losses compound accordingly. CelLink flex harnesses address this by carrying high voltage deeper into the GPU tray, keeping current lower across a longer path and reducing resistive losses before the final point-of-load conversion.
Q4: You describe power and cooling as things that should not fight for space. How do you co-design a flat power layer to work with liquid cooling in the same rack, and what does that integration unlock that assembling them separately cannot?
A: In conventional racks, power arrives via large-gauge, heavy, inflexible wire bundles, while liquid cooling relies on bulky pipes and hoses. Both compete for the same constrained volumetric space inside the tray. CelLink flex harnesses resolve this conflict by flattening power delivery to under 1mm in z-height, spreading it across tight spaces and allowing cooling infrastructure to occupy spaces where it actually needs to be.
The flat geometry also creates a natural thermal advantage: large, flat surfaces are far more effective for heat extraction than liquid cooling plates shaped around round wires or thick copper busbars. Co-designing the power and cooling layers together unlocks efficiency gains that assembling them separately simply cannot achieve.
Q5: CelLink came into the data center from high-volume EV manufacturing, where flexible circuits replaced bundles of hand-built wiring. What does that heritage teach about taking manual assembly out of rack build-outs, and where does rack-integrated power and cooling have to go next as density climbs?
A: CelLink's high-volume EV manufacturing heritage directly informs its data center approach. Flat, lightweight flex harnesses are well-suited to robotic pick-and-place assembly, and aluminum conductor designs proven in EVs and drones for weight and cost reduction translate naturally to rack environments where efficiency and thermal performance are equally critical.
The same principles that simplified EV wiring apply to rack build-outs, where loose cables and manual terminations introduce variability and assembly errors. CelLink flex harnesses can be placed directly adjacent to GPU components without cable management overhead. As rack density continues to climb, the next step is deeper integration, where the power delivery harness is co-designed and co-assembled with liquid cooling cold plates as a single unified subsystem.

Ayar Labs on Taking AI Scale-Up Beyond the Rack
Ahead of the AI Infra Summit this September, TechArena is spending the summer with companies up and down the AI stack to learn the latest on AI infrastructure requirements. Our conversations run from hyperscalers to storage, memory and networking, out to power, cooling, and the connectivity now holding these systems together.
I had the pleasure of chatting with Vishal Chandrasekar, head of product management at Ayar Labs, a co-packaged optics pioneer, to talk about what happens when AI scale-up outgrows the single rack. We covered why copper runs out of room, what an optical fabric has to get right, and how moving light into the package changes the economics of an AI data center. Here's what I learned.
Q1. AI scale-up is pushing systems beyond the boundaries of a single rack. What are chip and system designers asking for today that they did not need before the rapid growth of AI?
A: The fundamental requirement has changed. Chip and system designers are no longer optimizing only for the performance of an individual GPU, ASIC or switch. They are trying to connect thousands of accelerators so they can operate as a single unified system, with the bandwidth and latency needed to support increasingly large AI models and inference workloads.
That creates new demands around bandwidth density, power efficiency, reach and architectural flexibility. System designers need connectivity that can extend across multiple racks without the power penalties and signal-integrity challenges associated with driving high-speed electrical signals over longer distances. They also need a solution that fits into the standard fab, packaging flows and system-in-package architectures they already use.
This is where co-packaged optics becomes essential. Ayar Labs’ TeraPHY optical engine brings optical connectivity directly into the compute or switch package, while the SuperNova external light source provides the reliability and serviceability required for data center deployment. Together, they give designers a practical path to scale beyond the rack without rebuilding their design and manufacturing flows around a proprietary architecture.
Q2. Copper has supported generations of computing infrastructure. Where does it begin to constrain AI scale-up, and why can’t the industry simply continue improving electrical connectivity?
A: Copper remains effective over short distances, but its limitations become much more pronounced as bandwidth and scale-up domain sizes increase. Moving extremely high-bandwidth electrical signals requires more power as the distance grows, while signal integrity becomes increasingly difficult to maintain. That effectively traps high-performance AI scale-up architectures within individual racks.
This creates a difficult tradeoff. System designers can keep accelerators physically close together, concentrating enormous amounts of power and heat in increasingly dense racks, or distribute compute across multiple racks and accept a connectivity penalty. Neither is sustainable as AI systems grow.
CPO removes that tradeoff by using light to extend high-bandwidth, low-latency connectivity across tens of meters. Ayar Labs’ solution delivers up to 10 times higher bandwidth, 10 times lower latency and three to five times greater power efficiency than conventional copper and pluggable alternatives. That allows compute resources to be distributed across multiple racks while continuing to function as one scale-up domain.
Q3. Ayar Labs talks about enabling thousands of GPUs across racks to operate as a single unified system. What has to be true for an optical fabric to deliver that experience?
A: The optical fabric cannot become a new bottleneck. It has to deliver extremely high bandwidth and consistently low latency across the entire scale-up domain so accelerators can exchange data as though they were part of one tightly integrated system. It also has to consume very low power so as to not alter the economics of AI deployments which are often power constrained.
It also has to provide enough bandwidth density within the package. The TeraPHY optical engine uses microring modulator technology to deliver two terabits per second (Tbps) of shoreline bandwidth density per millimeter. That makes it possible to bring significant connectivity directly into an XPU or switch package without consuming the power and package area associated with traditional electrical interfaces.
Just as importantly, the architecture has to remain flexible. AI scale-up infrastructure is being deployed using UALink, PCIe, NVLink, ESUN and other standards and specifications. Ayar Labs has designed a protocol-agnostic architecture that can support evolving requirements without locking customers into one protocol, light-source provider or vendor-specific infrastructure or manufacturing flow. That combination of performance and compatibility is what turns optics from a component-level improvement into the foundation for a scalable AI fabric.
Q4. CPO has been discussed for years, but demonstrations are very different from high-volume deployment. What separates a promising optical technology from a manufacturing-ready solution?
A: The real test is whether the technology can be manufactured, integrated and serviced using the processes the semiconductor and data center industries already rely on. A successful demonstration matters, but customers also need confidence in reliability, supply, packaging, fiber attachment, thermal performance and production yield.
Ayar Labs has developed and shipped multiple generations of the TeraPHY optical engine, with thousands of units in customers’ hands. TeraPHY is built on proven silicon photonics and standard CMOS manufacturing, using a chiplet architecture and UCIe-based electrical interface designed to fit within existing ASIC and system-in-package designs.
Manufacturing readiness also extends beyond the optical engine itself. Ayar Labs has established partnerships across foundries, advanced packaging providers, OSATs, ASIC design services and ODMs. The company has developed reference designs and manufacturing flows at the package, board and rack levels, that support high-volume assembly and field serviceability.
CPO reaches volume when it becomes a natural extension of existing semiconductor design and manufacturing processes rather than a specialized architecture customers have to build around.
Q5. As scale-up domains grow to thousands of GPUs, how does moving from copper to CPO change the economics of the compute an AI data center can deliver?
A: The economics of AI infrastructure are increasingly determined by how efficiently a system can keep expensive compute resources working productively. It is not enough to add more GPUs if the network cannot feed them data quickly enough or if the power and cooling required to connect them consume an unsustainable share of the data center’s capacity.
Copper’s limited reach forces operators to concentrate compute within very dense racks or sacrifice bandwidth as they distribute it. CPO allows compute to be spread across multiple 100-kilowatt racks while preserving the high-bandwidth, low-latency connections needed for AI scale-up. That reduces thermal concentration and gives data center architects more flexibility in how they deploy power, cooling and compute capacity.
At the same time, Ayar Labs’ scale-up CPO solution provides five to 10 times greater bandwidth and three to five times greater power efficiency than conventional alternatives. As token volumes grow, those improvements can translate into more useful compute from the same power envelope and at a lower cost per token.
CPO is therefore not simply a faster way to move data. It changes the unit economics of AI infrastructure by enabling more accelerators to work together efficiently.

Precision Liquid Cooling: Iceotope's Case for the Whole Board
Leading up to the AI Infra Summit in September, we're continuing our conversations with AI infrastructure companies across the stack, from hyperscalers to storage, memory and network, to power and cooling and beyond.
I had the pleasure of sitting down with Simon Jesenko, chief executive officer/ chief financial officer of Iceotope, a precision liquid cooling player. Here's what I learned:
Q1: Iceotope’s precision liquid cooling seals the server and pulls heat off every component, not just the processor, with a dielectric coolant. What does cooling the whole board let an operator do that a cold plate on the chip alone can’t?
A: Cooling a server with direct-to-chip cooling may still require air cooling for the components that are not cooled by the cold plates. Cooling the whole server with dielectric fluid allows the operator to cool all heat generating components within the server: GPUs, CPUs, memory, networking, and PSUs.
Sealing the server into a protective enclosure and eliminating air cooling removes fan noise and allows the server to be positioned anywhere within the rack and the room. Cooling with dielectric fluid removes any fear that the operator may have about the proximity of water / PG25 inside the server. Servicing does not require the connection, disconnection, or modification of any plumbing containing water / PG25.
Find more information.
Q2: Precision liquid cooling isn’t only for the hottest GPUs. You cool storage, networking, and mainstream servers too. What kind of workloads and environments does that open precision liquid cooling up to?
A: This allows high-performance computing to move out of an air-cooled server room or data center, and to where it is actually needed. Customers can bring their compute clusters on-premises and deploy in harsh environments in a ruggedized chassis. Since Iceotope seals the server in a protective enclosure without fans, hardware is not exposed to external contaminants, so it can be deployed in harsh environments. Dielectric cooling fluid operates at temperatures up to 35° C, so it can effectively cool systems in extreme / outdoor environments
Q3: As rack densities pass what air and single-method approaches can carry, how far does chassis-level liquid cooling scale, and what changes along the way?
A: Hotter components, or more concentrated hot spots in the server can be cooled with fluid, depending on its temperature and flow rate. Hotter components require colder coolant and higher flowrates. The effectiveness of the coolant at (re)moving the heat is dependent on its specific heat capacity. Water has a higher heat capacity than dielectric fluid but it cannot come into direct contact with electronic components.
At scale, the factor against which all liquid cooling will be measured is the temperature of the coolant into the rack’s manifold (whether this is water/PG25 or dielectric. Currently, the target for this temperature is 45ºC. Any step (heat exchange) between two fluids or fluid to air is an inefficiency in the system (as some heat is lost in the process). As a result, the most efficient system is one which has fewer (or no) heat exchangers.
Q4: Your system captures almost all of the heat into liquid, so it can be reused rather than dumped. What does capturing heat that cleanly open up for an operator?
A: Captured heat can be reused in other deployments, for example a precision liquid cooled data center in a hotel basement could use the excess heat to heat the hotel pool. The heat capture and reuse ability turns datacenters into a community asset rather than a drain on resources.
Q5: What is the biggest thing still standing between precision liquid cooling and mainstream adoption, and how are you closing that gap?
A: Market perception is that precision liquid cooling is the same as tank immersion cooling, and requires too much infrastructure to deploy. In smaller form factors, the rising rack density in datacenters doesn’t have the same urgency for edge deployments. More information.

ASAPP's Priya Sawant on Building AI Agents Enterprises Can Trust
ASAPP SVP Priya Sawant joins the Data Insights podcast to discuss platform engineering, AI agent observability, and how engineering teams maintain trust while building with probabilistic technology.

From Experimenting to Measuring: Intel's Lynn Comp on AI
The AI Infra Summit is just around the corner, and TechArena is proud to return as a media sponsor. This summer, we've been trading notes with the companies building the AI stack, from silicon to systems, to hear where AI infrastructure requirements are really heading.
I had the pleasure of sitting down with Lynn Comp, Head of Global Sales and GTM for Intel's AI Center of Excellence. We covered what enterprises actually need from their infrastructure as they move from experimenting to measuring, why the real case for AI gets made on total cost and value per useful output rather than peak performance, and who answers for it when an AI system gets something wrong. Here's what I learned.
Q1: You’ve argued the hard problem in AI isn’t the model, it’s getting the same answer twice: determinism and time-based predictability. What does infrastructure have to deliver for an enterprise to trust agentic AI in production, and where does it fall short today?
A: Infrastructure needs to have very tight design constraints for a given AI based agent, avoiding the ability of an agent to exercise functionality beyond its intended purpose. Many of the exploits that have been uncovered come from an agent supporting prompts that go well beyond the intended purpose of the agent’s function. Simple, straightforward functional design and thinking of agent design like building an appliance helps keep the architecture clean, which then has the byproduct of being more deterministic and predictable.
Q2: You spend your days with enterprises operationalizing AI. What do they most need from their infrastructure to make it pay off, and what has shifted this past year as they move from experimenting to measuring?
A: The baseline need is to have a data architecture that can support AI operations – both using business data as a baseline input as well as during AI-based workflows. The AI is generic until it applies your business information and context, but it is difficult to see ROI from AI that spends the majority of tokens on the data input processes rather than getting insights from the underlying data. Beyond that, the next most important question relates to enterprise governance since AI operations can change the company posture related to copyright, underwriting and regulatory compliance questions.
As companies shift from experimenting to measuring, I’m seeing harder questions being asked about private and hybrid AI as the true costs of frontier models hosted in hyperscaler data centers become more obvious. No CFO is happy when they are told “I don’t know how much budget I will need for AI Ops at scale, nor can I guarantee I can hit that budget” by their sysadmins and IT architects.
Q3: Much of the AI conversation fixates on the biggest, most expensive hardware. Where does the real case get made on total cost and value per useful output, rather than peak performance?
A: One of the hardest benefits to articulate and demonstrate on a balance sheet is better operational efficiency, since it’s not a hard cost you can show gains or reductions in a way similar to when purchasing hard goods or services. Because of that, buying new expensive hardware that has overhead just from having to deploy new cooling strategies is very difficult to pencil out against “went from 7 days to 5 minutes in developing dashboards that report on overall fleet health”. The current approach on explaining the value in that example is to claim fewer employees are required, which is counterbalanced by increasing token costs from suppliers.
I hear from multiple enterprises that they’ve applied the multi-cloud skills developed over the last 10 years to AI. They are learning to mix and match privately optimized AI and small language models that have been fine-tuned with judicious application of frontier models, hyperscaler services and neoclouds. For the health-meter dashboard example, prototyping is done on a frontier model and then the workflow is moved to a local SLM to improve operational economics.
Q4: The industry is moving from buying components to running one integrated machine. From where you sit with enterprises, is that the real shift, and what does it change about what they buy and how they operate?
A: The combinatorial explosion with agentic AI between discrete agents, frameworks, disparate API ecosystems and overlapping capabilities is resulting in security gaps, version conflict and unpredictable TCO. At the same time, market changes on the virtualization front are causing enterprise decision makers to be very cautious about anything that resembles vendor lock-in since even stable, trusted suppliers can suddenly be acquired by a larger company with very different customer management principles. I have already seen enterprises creating their own interfaces and allowing model selection under their internal APIs so model-independence is built in from the start, and I suspect similar architecture principles will be carried forward where there are important control points in an enterprises’ tech stack.
Q5: You’ve pointed out that most enterprises still can’t answer a basic question: when an AI system produces a harmful or biased result, who is accountable? What has to live in the infrastructure itself, the telemetry, the provenance, the controls, before anyone can answer that honestly, and how much are enterprises still taking on faith today?
A: The telemetry and the provenance for data as well as decision traceability have to be operational code running within the AI systems and the overall orchestration of the AI operations. Any decision that would be difficult to defend in a current regulatory framework needs to have a human in the loop, and at the same time, a human has to have the right insights support from the AI Operations so the human isn’t overwhelmed with overwhelming amounts of data in the process.

How My 2026 Automotive Predictions Are Faring: A Mid-Year Scorecard
It’s hard to believe that we are now midway through 2026. Once again, I am looking back at my crystal ball to see how the three major trends I predicted would meaningfully affect the automotive industry have actually played out.
To be clear, these weren’t thoughts pulled out of thin air; they reflected observations of events that had already transpired and that I expected would see significant traction. If you’ve been tracking the industry lately, you’ve probably noticed that the turmoil I described has only intensified. This isn’t a cyclical downturn; it’s a fundamental rewiring of how cars are conceived, built, and sold. And the scorecard, I’m pleased to report, is largely validating what I foresaw.
1. AI-Driven Product Development: Hit the Bullseye (With a Catch)
On AI-driven product development, the prediction has hit the bullseye. As of early 2026, 91% of global OEMs have moved generative AI beyond proof-of-concept into production use, with design cycle reductions of 65–80% are now being reported across the industry. Physics-informed neural networks have reduced the need for physical prototyping by 70%. The 50% reduction in development costs I anticipated is now being exceeded by early adopters. What once demanded months of tedious traceability mapping for ASIL (Automotive Safety Integrity Level) compliance is now orchestrated by agentic AI systems that provide 24/7 compliance monitoring. The competitive moat has indeed shifted from engineering expertise to the sophistication of AI training data and computational infrastructure - exactly as I predicted. However, an extreme reliance on AI has proven to have backfired on Ford as they have recently re-hired over 300 “grey beard” engineers to fix Ford’s quality systems. Overreliance on automated AI tools had negatively impacted their quality assurance pipelines, leading to an unsustainable spike in vehicle recalls.
2. The Software-Defined Vehicle (SDV) Divide Widens
The software-defined vehicle divide has widened even faster than I expected, and the incumbent carnage has been brutal. Ford’s cancellation of its “Lightning” SDV platform was merely the opening act; in 2026, they have since scrapped the all-electric F-150 project entirely to redirect capital toward expanding its hybrid lineup, acknowledging that its EV division is projected to lose up to $5.5 billion in a single year. GM delayed its electric truck production expansion to at least mid-2026 and reintroduced plug-in hybrids it had previously discontinued. Meanwhile, tech-native companies like Tesla and Rivian, together with Chinese OEMs like BYD and NIO, continue to push new functions weekly via over-the-air (OTA) updates while legacy OEMs remain shackled to three-to-five-year hardware refresh cycles. The market bifurcation into haves and have-nots is happening at a heightened pace, and the estimated three-to-four-year delay in SDV deployment for traditional OEMs is creating a compounding disadvantage that grows more insurmountable by the quarter.
3. Incentive Withdrawals, Hybrid Bridges, and the European Twist
On the incentive withdrawal and EV momentum front, the narrative has played out almost exactly as scripted - but with a twist I didn’t fully anticipate.
The withdrawal of EV tax credits in the US in September 2025 triggered the predicted pullback: battery electric vehicle (BEV) sales fell 23% year-on-year in Q1 2026, and plug-in hybrid (PHEV) sales collapsed 53%. Ford and GM’s tactical retreat to hybrids is precisely the “rational bridge technology” response I described. However, what I underestimated was the speed of the policy rebound. France and Germany renewed or reintroduced purchase incentives in early 2026, and European BEV sales surged 36% year-on-year in Q1 as a result. The hybrid resurgence is real - hybrid sales in Europe’s top five markets broke the one-million barrier for the first time in any quarter, reaching a record 42% market share - but the fundamental EV cost-crossover momentum remains unstoppable. This is particularly true in China, where BYD and Geely continue delivering 300-mile range vehicles below $20,000.
The Strategic Takeaway
The strategic implications I laid out are proving more urgent than ever. The great bifurcation is no longer theoretical; it is unfolding in real-time across earnings calls, factory announcements, and market share tables.
Companies that treated AI-driven design as a productivity tool rather than the new basis of competition are now scrambling to catch up. However, as Ford found out, there is such a thing as too much of a good thing. OEMs that attempted to orchestrate SDV platforms across fragmented supplier ecosystems are watching their architectures collapse under their own weight. And those that tethered their EV strategy to Western policy cycles are discovering that policy is a fickle foundation.
The companies thriving are the ones that recognized automotive manufacturing has become a data and software business that happens to produce vehicles. The laggards are still arguing about whether the transformation is real.

The Knowledge Loop Problem: When AI Output Becomes the Next Input
As enterprises let AI-generated summaries, tickets, notes, and briefs flow back into retrieval systems, the next trust challenge is measuring how far every answer is from an authoritative source.
An AI assistant summarizes a customer call and notes that the customer seemed frustrated about renewal timing. That summary is saved into the customer relationship management (CRM) system.
A week later, another assistant retrieves the CRM note and generates an account-risk brief. It classifies the customer as a potential retention risk.
A month later, a planning assistant uses that risk brief to recommend executive attention.
Nothing obviously failed. The CRM was current. The retrieval system found relevant context. The planning assistant produced a reasonable recommendation.
The customer may well be a real retention risk. That is not the point. The problem is that the organization may no longer know whether it is acting on evidence or on an AI’s tonal read of a conversation dressed up as a finding.
The hops did not add evidence. They added confidence.
That is the knowledge loop problem. It is becoming one of the quieter risks in enterprise AI, and most organizations have no way to see it.
Enterprise AI Has Become Read-Write
For years, enterprise knowledge systems were built around a mostly human write path. Humans wrote the documents, set the policies, and entered the records. AI systems, when they arrived, mostly consumed that material. They retrieved, summarized, and answered against knowledge that people had authored.
That arrangement is ending.
Newer AI systems increasingly write back into the knowledge layer. They generate meeting recaps, support responses, incident summaries, account briefs, ticket classifications, and draft documentation. Those artifacts do not stay in a chat window. They are saved into CRMs, ticketing systems, wikis, knowledge bases, and shared drives. Once stored, they are indexed. Once indexed, they are retrieved. Once retrieved, they become context for the next AI system.
In many workflows, the knowledge supply chain is no longer purely human-authored at the source. AI output has become enterprise input.
The Risk Is Circularity, Not Just Staleness
An earlier discipline already exists for one version of this problem. Knowledge freshness asks whether information is still current: whether a policy changed, whether a definition shifted, whether an old version is still being retrieved alongside a new one.
This is a different question. Freshness asks whether the information is still current. Grounding distance asks how many interpretive layers separate an answer from evidence.
The freshness failure sounds like this: the policy changed, but the system used the old one. The knowledge loop failure sounds like this: the system used a summary of a summary of a note, and no one realized the original source was never strong enough to support the conclusion. Same trust family, different mechanism. One is about knowledge aging. The other is about knowledge losing direct contact with the evidence underneath it.
Humans have always summarized other humans, so it is worth being precise about what is new. Human interpretation carried natural friction. It took time. It left named authorship. It usually moved through visible review paths. A chain of five human summaries took weeks and left a trail of people who could be asked what they meant. An AI chain of five interpretations takes seconds, runs at high volume, and flattens authorship into the system. The problem is not that interpretation degrades. Interpretation has always degraded across hops. The risk is that it now degrades silently and at scale, and that each polished restatement tends to read as more certain than the hedged original it came from. Uncertainty gets laundered into authority as generated artifacts move through the knowledge layer.
This is not the concern that models trained on synthetic content degrade over time. That is a training-data problem. This is a retrieval and inference-time problem. The model may never be retrained. The same model can simply retrieve a generated summary, treat it as context, and build another answer on top of it. Many enterprises are already running copilots and agentic workflows over internal repositories. Those systems may be carefully grounded at first, but if the repository fills with generated interpretations of earlier generated interpretations, grounding becomes harder to reason about even when nothing about the model has changed.
Grounding Distance
Grounding distance is the number of interpretive hops between an AI-generated output and a governed source of truth.
It can be described as a rough ladder. The ladder is an illustration, not a precise scale.
Distance 0: The answer is grounded directly in a governed source of truth, such as a system-of-record field, an approved policy, a controlled document, or an authoritative source.
Distance 1: The answer relies on a first-order interpretation of an authoritative source. In the opening example, the original call summary sits here. It is one step from the conversation it describes.
Distance 2: The answer relies on an interpretation of an interpretation. The account-risk brief sits here. It was built from the CRM note, not from the call, the renewal system, or an explicit customer statement.
Distance 3: The answer relies on a generated artifact that is already multiple steps removed from the evidence. The executive recommendation sits here. It was built from the risk brief, which was built from the summary.
Distance 4 and beyond: Generated artifacts repeatedly become source material for later generated artifacts, and the answer is several layers removed from any original record.
The ladder counts hops only. It says nothing yet about who wrote each layer or whether anyone checked it. That is deliberate, because authorship and approval are a separate axis.
Authorship, approval, and visibility modify the effective risk of each hop. A human-written note, an AI-generated summary, and a human-approved AI summary may all sit at the same nominal distance, but they should not carry the same trust weight unless the review, the source linkage, and the ownership are visible. A meaningful human validation, one that actually checks the layer against the original record, can reduce effective distance. A rubber stamp should not. The point is not whether the author was human or machine. The point is how many interpretive layers separate the answer from evidence, and whether those layers can be seen.
It Is Computable Where Provenance Is Captured
Grounding distance is not only a metaphor. It is computable wherever provenance is captured. It can be derived from metadata that enterprise AI systems should already be collecting: artifact origin, source type, generation method, approval status, retrieval path, and version lineage. If a platform knows that a retrieved brief was generated from a note that was generated from a call summary, it can count the hops. This is an extension of lineage work many teams have already started, not a separate measurement discipline to invent from scratch.
The limitation appears where provenance breaks. The hardest cases are the artifacts that escape the metadata layer entirely: an AI summary pasted into a free-text CRM field, a generated meeting recap copied into a project note, a draft recommendation saved without origin tags. The moment generated content is detached from its lineage and re-entered as plain text, its grounding distance becomes invisible. The system sees a source. It does not see that the source was an answer.
Those artifacts are not edge cases. They are where the risk concentrates. The work of measuring grounding distance is mostly the work of making sure generated content cannot enter the knowledge layer without carrying where it came from.
A Citation Is Not the Same as Evidence
This is the next layer of a trust question enterprises have already started asking. The work of trusting an AI-created output depends on provenance, currency, policy compliance, and explainability. The knowledge loop problem sharpens the first of those. Provenance is no longer only about where the retrieved source came from. It is about whether that source was itself already a generated answer.
Part of what makes this hard is that enterprise systems tend to assign authority by location. Content in the CRM is treated as customer context. Content in a ticketing system is treated as operational history. Content in a knowledge base is treated as reusable guidance. But location does not prove authority. A generated summary saved into a trusted system does not become a trusted fact, and a meeting recap copied into a project page does not become validated knowledge because it is searchable. When generated artifacts move across systems without origin metadata, authority becomes detached from accountability. The artifact looks official, but no one can say who approved it, what source it came from, or whether it was ever checked against the original record.
A grounded citation is not the same as a grounded answer. A system can retrieve the right document, cite it cleanly, and still be standing several interpretive hops from anything a human or a system of record ever verified.
Three Moves
Managing this does not require a transformation program. It requires three operating decisions.
The first is to track origin type as first-class metadata. Every artifact in the knowledge layer should carry whether it is a system-of-record entry, human-authored, AI-assisted, AI-generated, or human-approved. Origin type should be as routine to capture as a timestamp. Without it, none of the rest is possible.
The second is to rank governed sources above generated artifacts. Retrieval systems should not treat an AI-generated summary as equal to a governed record, an approved policy, or an authoritative definition. When both are available, the governed source should win, and the generated artifact should be treated as commentary on it rather than a substitute for it.
The third is to cap grounding distance for high-stakes workflows. For compliance, finance, legal, healthcare, customer-impacting, executive, or operational decisions, systems should not act on long chains of generated interpretation without returning to an authoritative source or passing through meaningful human validation. The higher the stakes, the shorter the allowed distance.
The Next Governance Question
Enterprise AI will not fail only because models are wrong. It may fail because systems begin trusting polished artifacts whose connection to evidence has grown too distant to inspect. The output looks finished. The citation looks valid. The chain behind it is generated all the way down.
The next governance challenge is not only controlling what models generate. It is controlling what generated content is allowed to become source material for the next decision.
We learned to ask where data came from. Now we have to ask whether the source was itself an answer.

At Discover, the Importance of the AI Network was on Full Display
I started my career in network, before knowing word one about silicon learning all about the dynamics of data movement. It was with this lens that I took in HPE's acquisition of Juniper Networks, seeing the move as more than just Total Addressable Market (TAM) expansion but as a strategic technology acquisition. In an era where everything must innovate to keep up with AI stack requirements, the network is becoming a rising constraint. And with HPE seeking to foster a new season of relevance and leadership to the AI Data Center, controlling the delivery of leading network infrastructure is a perfect match with their current portfolio of data center solutions for the enterprise.
Unraveling the Network Portfolio
Since the acquisition officially closed in July 2025, the question of portfolio integration has been top of mind. Of course, HPE had Aruba, a company it had already acquired, so why Juniper? I've given a head nod to the complexity of this portfolio lineup last year as the HPE teams tried to make sense of this tossed salad of solutions. And really the answer is that both will make sense in the end, and Juniper specifically because it offers something the industry needs right now - automation and scale of network capabilities that will deliver data to increasingly demanding compute clusters. To deliver AI, data center infrastructure must embed AI in meaningful ways. Juniper's vision, and its Apstra technology foundation, will provide enterprises the automated control that is required to meet this moment.
Scaling Autonomy for Agentic AI
I am curious how this technology direction will influence HPE's broader portfolio as enterprises scaling agentic AI deployments demand infrastructure that is far more nimble than what we've cobbled together in the past. Autonomous control of infra, not at the component or even single box level, but as a logical row, pod, or data center level entity. With Juniper, HPE completed its infra portfolio and also got an injection of technology to lay a foundation to get there. And TechArena is excited to see what comes next.


From AI Land Grab to Full Stack: Targeting the Orchestration Layer
On June 16, a rocket company bought a coding assistant for $60 billion.
Four days off the largest IPO in financial history, SpaceX agreed to acquire Anysphere, the startup behind the AI coding tool Cursor, in an all-stock deal. It was the biggest purchase of a venture-backed company on record. The buyer builds reusable rockets and beams internet from low orbit. The target builds software that writes code. On paper, the two have nothing to do with each other, and that is the whole point.
In March, we published an article highlighting the shift from a race for the smartest model to a scramble for the power, pipes, and provenance that make a model useful. The last 90 days of acquisitions moved the storyline again. The layers are no longer holding as separate tiers. The action shifted to the layers above the model, and orchestration became the hottest prize of all. A handful of owners are now reaching to control every tier at once. And vertical integration stopped being a strategy. It became the entire game.
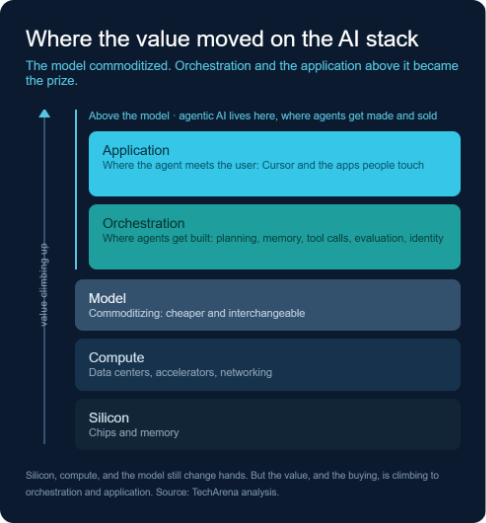
Picture the AI stack as five tiers. For three years, the model at its center was the product and the prize. That has flipped. Models keep getting cheaper and more interchangeable, and the value is climbing to the two tiers above them. Orchestration is where an agent gets built: planning, memory, tool calls, evaluation, the identity it uses to log in. The application layer is where that agent meets a user, the way Cursor meets a developer. Agentic AI lives in those upper tiers, software that plans and acts instead of only answering. The buying is a race to own that ground.
The Quarter That Broke the Charts
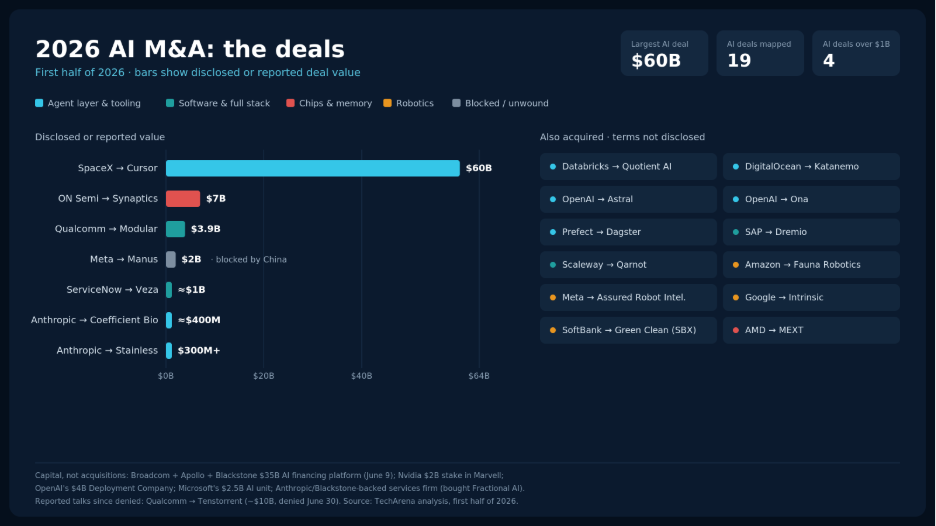
Global M&A cleared $1.2 trillion in the first quarter of 2026. The number of deals fell from a year earlier, but the ones that closed were bigger. Twenty-two transactions topped $10 billion, a quarterly record. AI drove four of the six largest.
The shape of the money is as telling as the size. Equity-stake purchases, not clean acquisitions, made up 29% of deal volume. OpenAI’s raise, which closed at $122 billion, counted as three of the quarter’s biggest transactions on its own. Anthropic’s $30 billion round tied for fourth. The line between buying a company and funding one has gone soft, and that blur runs through everything below.
The Orchestration Layer Is the New Prize
Pull the megadeals aside and look at what actually changed hands this spring, and almost nobody bought a model. They bought agents, the applications people actually use, and the orchestration machinery that makes those agents work.
Cursor is an agent that writes code. Manus, the autonomous agent Meta agreed to buy earlier in the year for $2 billion before regulators stepped in, runs multi-step jobs on its own. Around those headline targets, a quieter shopping spree filled in the plumbing. Anthropic paid a reported figure of more than $300 million for Stainless, the tooling startup whose SDKs and MCP servers are used by OpenAI, Google, and Cloudflare. Databricks bought Quotient AI to grade agents on their own production traces. DigitalOcean took Katanemo Labs to run agentic inference. ServiceNow moved on Veza to handle identity when the thing logging in is a machine, not a person. OpenAI absorbed Astral, the team behind the open-source Python tools half the AI world already builds on, and bought Ona, the cloud-execution startup once known as Gitpod, so its Codex agents can run for hours inside a customer’s own cloud. SAP closed its purchase of Dremio in early July to turn its data platform into an agent-ready lakehouse. The consolidation reached the orchestrators themselves. On July 13, Prefect agreed to buy Dagster Labs, folding the two most widely adopted successors to Apache Airflow into one workflow engine that runs data pipelines and agentic jobs and governs agents through the Model Context Protocol.
Line them up and a category snaps into focus. Coding, autonomy, evaluation, inference, identity, tooling, workflow. None of it is a foundation model. All of it is the orchestration layer, the tier that turns a model into something that works and can be trusted to run without a human watching every keystroke. Read another way, it is a list of the bottlenecks between a clever demo and a production system, each one bought by the company that felt the pinch first.
“Everyone has been focused on who is winning the AI model race. The bigger question is who controls the production stack,” said Laura St. John, TechArena co-founder and advisor. “We’re seeing companies acquire the technologies that turn AI from pilots into production-ready platforms, capturing the layers that make AI deployable, manageable, and repeatable in the enterprise. Cloud followed a similar path: proprietary ecosystems dominated early, then enterprises pushed for portability and choice. The question is whether AI follows the same trajectory once buyers begin to feel the tradeoff between capability and lock-in.”
Buying the Whole Stack
The other force is the one SpaceX put in neon. Buying Cursor is not a coding play. It is the capstone on a structure that already runs from the power source to the orbit to the social feed. Reusable launch. Starlink satellites. The xAI merger that folded in models and the X platform. Now the application layer, the agent that sits in front of a developer all day.
Qualcomm reached the other way. At its June 24 Investor Day, the smartphone chip company confirmed a $3.92 billion all-stock deal for Modular, the software startup founded by Chris Lattner, the engineer behind LLVM and Apple’s Swift. Modular’s platform lets AI models run across CPUs, GPUs, NPUs, and custom silicon without rewriting code for each one, a direct strike at the CUDA software lock-in that has kept developers tethered to Nvidia. Qualcomm wrapped it into a new Dragonfly data-center chip line, lined up anchor commitments from Meta and Microsoft, and may not be done. The company has reportedly been in talks to buy Tenstorrent, Jim Keller’s RISC-V accelerator startup, for as much as $10 billion, a deal that stayed unconfirmed at the event.
SpaceX bought its way up the stack toward the user. Qualcomm bought its way across it, from silicon into the software that decides which silicon a developer can use. Different directions, one instinct: own the layer you are missing.
The frontier labs are running the same move in a lower key. OpenAI stood up a Deployment Company, a $4 billion services venture, and bought a consulting firm to staff it with forward-deployed engineers. Anthropic helped stand up a new Blackstone-backed enterprise-services firm, reinforcing the tooling layer with Stainless, and pushed into biology with a roughly $400 million deal for the drug-discovery startup Coefficient Bio.
In July, Microsoft matched the pattern from its own perch, committing $2.5 billion and 6,000 people to a dedicated AI deployment unit. These are not the moves of companies that see themselves as model vendors. They are the moves of companies building everything above and below the model, then selling the whole stack as one thing.
Lynn Comp, vice president and head of global sales and go-to-market for Intel’s AI Center of Excellence and a TechArena Voice of Innovation, reads the pivot as a structural inevitability.
“While the frontier models were largely focused on a race with one another and the pursuit of ‘AGI’, it was clear that any general-purpose model would likely fall into a class of software known as middleware, that historically struggles to maintain stickiness and margin,” she said. “The fact that the frontier labs and their hyperscaler hosts are now investing in services confirms that the model alone will not maintain long term value when it comes to the enterprise buyer.”
The reflex reaches past software. In space, the field SpaceX helped define, Rocket Lab agreed in late June to buy the satellite operator Iridium for $8 billion, stitching launch and network together to compete with Starlink. The move is the same whether the target is an agent or an orbit.
The moat has become the number of layers you control.
Intelligence Climbs Into the Machines
As the software layers consolidated, a parallel land grab opened in the physical world. Amazon bought Fauna Robotics, a humanoid startup aimed at everyday spaces rather than warehouses. Meta picked up Assured Robot Intelligence to sharpen the models that run robot bodies. Google folded in Intrinsic, the industrial-robotics software group it had been incubating. SoftBank folded Green Clean Commercial into a new Smart Building X unit.
The logic is the one driving the software deals, pointed at hardware. If the goal is owning the full stack, the stack does not stop at the screen. It runs into the arm, the gripper, the chassis. AI has lived on a screen. Its next form factor has arms, and those companies are changing hands now.
The Money Got Strange
When a single funding round outweighs most of the quarter’s acquisitions, the league tables stop measuring what they used to.
The circularity is hard to miss once you see it. Nvidia invested $2 billion in Marvell, one of its own suppliers, in March. Apollo and Blackstone led a reported $35 billion financing platform, announced June 9, tied to Broadcom’s AI infrastructure and the compute buildouts of labs including Anthropic and OpenAI. Chips, capital, and compute now flow in loops between the same dozen companies. A supplier funds a customer who buys from a partner who invests back in the supplier.
The Squeeze Moves to Memory
The buying runs all the way to the sensor. ON Semiconductor struck a $7 billion deal for Synaptics on June 25 to push into physical AI, the chips that let machines see, touch, and read a room. When the prize is the whole stack, the silicon that feeds the robot counts as much as the model that steers it.
Comp offers a way to read where the buying lands next.
“In database and data platforms there is an operational triad called ‘ETL’ (Extract, transform, load). For hardware infrastructure, there is an equivalent that holds true at every layer of the tech stack from inside the compute pipeline to the SOC up to the datacenter itself: First: Network/Bandwidth. Second: storage/memory and lastly: processing/compute. The hardware industry is always trying to achieve balance between the three and always over-building in one domain, only to discover the bottleneck moves to one of the other two,” she said.
The squeeze is moving to memory. AMD bought MEXT on June 15, a Santa Clara startup whose software makes flash behave like DRAM and stretches usable memory without buying more of it. The timing is not incidental. DRAM supply is growing slower than demand, and Gartner expects combined DRAM and SSD prices to climb roughly 130% by the end of 2026. When memory gets scarce, the companies building AI infrastructure stop waiting for the market to loosen and start buying the engineers who can wring more out of what they already have.
Memory gave the clearest read of all. On June 24, Micron, the only U.S. maker of the high-bandwidth memory that feeds every major AI accelerator, posted record fiscal third-quarter revenue of $41.5 billion, gross margin of 84.9%, and earnings of $25.11 a share, past every Wall Street estimate. It guided the next quarter to roughly $50 billion, said it is sold out of HBM into 2027, and watched its stock jump about 15%. The largest hyperscalers have committed more than $725 billion to AI infrastructure this year, and the industry watches Micron to learn whether that spending is holding. The answer was not subtle. Memory is where the buildout shows up first, and the meter is still climbing.
Governments are the one force pushing the other way, and they cut from two directions. The clearest is the agent deal that did not close. Beijing blocked Meta’s $2 billion purchase of Manus and ordered the company to unwind it, treating the startup’s China-developed technology as an export to control rather than an asset to sell. The other direction is antitrust. When Nvidia took Groq’s inference technology and talent late last year in a licensing-plus-hiring arrangement rather than a clean buyout, Sens. Elizabeth Warren and Richard Blumenthal sent a letter asking whether the structure was an end run around review. Expect more of both questions. The deals are getting creative precisely as the scrutiny gets sharper.
What the Buying Leaves Open
All of that dealmaking points to a question not answered in the last few months. Cloud computing became a utility the day it stopped mattering which cloud you used, once a portable unit of work and a neutral steward, the Cloud Native Computing Foundation, let enterprises move between providers at will. AI has the compute and the model APIs. It does not yet have a portable layer or a neutral body to govern one. The candidates keep getting bought before they can open, from agent tooling to the run-anywhere software Qualcomm just folded into its own silicon.
A few buyers are moving the other way. On July 10, Scaleway, the sovereign European cloud arm of the iliad Group, bought the French HPC specialist Qarnot and built the deal on open standards rather than around them. Both companies design their infrastructure to Open Compute Project specifications, and both pitch portability and freedom from lock-in as the product itself. Qarnot brings patented liquid cooling that recovers up to 95% of the heat its servers throw off and pipes it into district heating networks, already running in cities such as Brescia, Italy. Set against the megadeals, it is a small transaction. It also points straight at the layer the open camp still hopes to build, and it does so from Europe, where sovereignty gives portability a second reason to exist.
History says an open wave still comes. It came for cloud after years of walled gardens like AWS, and the fragmented open efforts in AI are moving faster than cloud’s early ones did. The push has not hit its tipping point, the moment that shoves it to the front. When it does, expect it to run through the groups built for exactly this fight, the Open Source Initiative and the Linux Foundation. That is the open question underneath all the buying.
The TechArena Take
For startups, the gap only widened. In our March AI M&A article, I called it the integration gap, the distance between owning one clever capability and owning enough of the stack around it to deliver that capability and govern it in production. A year ago, that gap was a step. Now it is a canyon.
If your product is one sharp capability without the layers around it, you are not a platform. You are a feature, and features get bought or buried. The companies that sold in the first and second quarters of 2026 were a missing floor in someone else’s building. The ones that did not sell are racing to add floors of their own before the offer comes.
For enterprises, the vendor you pick now arrives with a stack bolted on. Lock-in used to mean a model or a database. It is starting to mean everything underneath, from the agent down to the silicon. That is convenient right up until it is not. The demand worth making now, loudly, is for portability. No vendor will offer it unprompted.
For the industry, the contest is no longer about owning a layer. It is about how few players end up owning the whole run, from the power plant to the prompt. Whether AI ends up a utility or a set of fiefdoms turns on whether a neutral, portable layer survives the buying. That is the story to watch, and the one we report next.
-----
Endnotes
1. Reuters, “Global first-quarter M&A exceeds $1.2 trillion, led by AI,” April 1, 2026. https://www.reuters.com/business/finance/global-first-quarter-ma-exceeds-12-trillion-led-by-ai-2026-04-01/
2. CNBC, “SpaceX to acquire the AI coding startup Cursor for $60 billion,” June 16, 2026; corroborated by TechCrunch, June 16, 2026. https://www.cnbc.com/2026/06/16/spacex-spcx-cursor-acquisition-ipo.html
3. Rachel Horton, “2026 AI M&A: The Great Shift from Models to Infrastructure,” TechArena, March 10, 2026. https://techarena.ai/content/2026-ai-m-a-the-great-shift-from-models-to-infrastructure
4. TechRadar, “Meta buys Manus for $2 billion to power high-stakes AI agent race,” 2026 (announced deal). https://www.techradar.com/pro/meta-buys-manus-for-usd2-billion-to-power-high-stakes-ai-agent-race
5. CNBC, “China blocks Meta's acquisition of AI startup Manus,” April 27, 2026 (China's NDRC ordered Meta to unwind the deal). https://www.cnbc.com/2026/04/27/meta-manus-china-blocks-acquisition-ai-startup.html
6. TechCrunch, “Anthropic has acquired the dev tools startup used by OpenAI, Google, and Cloudflare” (Stainless), May 18, 2026. https://techcrunch.com/2026/05/18/anthropic-has-acquired-the-dev-tools-startup-used-by-openai-google-and-cloudflare/
7. PrivSource, “Databricks Acquires Quotient AI to Power AI Agent Evaluations,” March 19, 2026. https://www.privsource.com/acquisitions/deal/databricks-acquires-quotient-ai-to-power-ai-agent-evaluations-4dS397
8. PrivSource, “DigitalOcean Acquires Katanemo Labs to Expand Agentic AI Inference Cloud,” April 2, 2026. https://www.privsource.com/acquisitions/deal/digitalocean-acquires-katanemo-labs-to-expand-agentic-ai-inference-cloud-VnSWDA
9. ServiceNow Newsroom, “ServiceNow to Expand Security Portfolio With Acquisition of Veza's Leading AI-native Identity Security Platform,” 2025; deal closed March 2, 2026. https://newsroom.servicenow.com/press-releases/details/2025/ServiceNow-to-Expand-Security-Portfolio-With-Acquisition-of-Vezas-Leading-AI-native-Identity-Security-Platform/default.aspx
10. Crunchbase News, “Data: OpenAI Has Already Done Nearly As Many M&A Deals In 2026 As It Did All of Last Year” (Astral), 2026. https://news.crunchbase.com/ma/data-openai-2023-2026-acquisitions-open-source-astral-promptfoo/
11. SAP News Center, “SAP Completes Dremio Acquisition,” July 2026. https://news.sap.com/2026/07/sap-completes-dremio-acquisition/
12. The Guardian, “Elon Musk is taking SpaceX's minority shareholders for a ride,” February 3, 2026. https://www.theguardian.com/business/nils-pratley-on-finance/2026/feb/03/elon-musk-is-taking-spacexs-minority-shareholders-for-a-ride
13. Network World, “Qualcomm's $3.9 billion purchase of Modular aims to change the data center dynamic,” June 24, 2026; see also Quartz, June 24, 2026. https://www.networkworld.com/article/4189098/qualcomms-3-9-billion-purchase-of-modular-aims-to-change-the-data-center-dynamic.html
14. TechTimes, “Qualcomm Bets $14 Billion on Cracking Nvidia's AI Monopoly With RISC-V and an Open Compiler,” June 24, 2026; Qualcomm Investor Relations, Investor Day 2026. https://www.techtimes.com/articles/319017/20260624/qualcomm-bets-14-billion-cracking-nvidias-ai-monopoly-risc-v-open-compiler.htm
15. The Information, “Qualcomm in Talks to Buy Tenstorrent to Expand AI Chip Capabilities,” June 15, 2026; see also TechTimes, June 17, 2026. https://www.theinformation.com/articles/qualcomm-talks-buy-tenstorrent-expand-ai-chip-capabilities
16. OpenAI, “OpenAI launches the OpenAI Deployment Company to help businesses build around intelligence,” 2026. https://openai.com/index/openai-launches-the-deployment-company/
17. Bloomberg, “Anthropic-Backed AI Services Firm Acquires Fractional AI in First Deal,” May 21, 2026. https://www.bloomberg.com/news/articles/2026-05-21/anthropic-s-new-consulting-venture-makes-its-first-acquisition
18. FierceBiotech, “Anthropic acquires stealth AI startup Coefficient Bio in $400M deal: reports,” 2026. https://www.fiercebiotech.com/biotech/anthropic-acquires-stealth-ai-startup-coefficient-bio-400m-deal
19. TechCrunch, “Microsoft launches its own AI deployment company with $2.5 billion commitment,” July 2, 2026; see also CNBC, July 2, 2026. https://techcrunch.com/2026/07/02/microsoft-launches-its-own-ai-deployment-company-with-2-5-billion-commitment/
20. The Motley Fool, “Rocket Lab Announces a Big Acquisition That Could Be Problematic for SpaceX” (Iridium, $8 billion), July 7, 2026. https://www.fool.com/investing/2026/07/07/rocket-lab-announces-a-big-acquisition-that-could/
21. PrivSource, “Amazon Acquires Fauna Robotics,” March 27, 2026. https://www.privsource.com/acquisitions/deal/amazon-acquires-fauna-robotics-deSlo5
22. TechCrunch, “Meta buys robotics startup to bolster its humanoid AI ambitions,” May 1, 2026. https://techcrunch.com/2026/05/01/meta-buys-robotics-startup-to-bolster-its-humanoid-ai-ambitions/
23. PrivSource, “Google Absorbs Intrinsic to Build Physical AI for Industrial Robotics,” March 1, 2026. https://www.privsource.com/acquisitions/deal/google-absorbs-intrinsic-to-build-physical-ai-for-industrial-robotics-4dSW72
24. PrivSource, “SoftBank Robotics America Acquires Green Clean Commercial to Launch Smart Building X (SBX),” March 24, 2026. https://www.privsource.com/acquisitions/deal/softbank-robotics-america-acquires-green-clean-commercial-to-launch-smart-building-x-sbx-2VSmwj
25. Crunchbase News, “Sector Snapshot: Semiconductor Startup Funding Still Running Hot,” 2026 (Nvidia's $2 billion strategic investment in Marvell, NVLink Fusion). https://news.crunchbase.com/semiconductors-and-5g/chip-startup-funding-2026-cerebras-matx-ayar-labs-ipos-nvda/
26. PR Newswire, “Broadcom, Apollo, and Blackstone Establish Landmark Strategic Platform to Accelerate More Than 20 Gigawatts of Global AI Deployments,” June 2026. https://www.prnewswire.com/news-releases/broadcom-apollo-and-blackstone-establish-landmark-strategic-platform-to-accelerate-more-than-20-gigawatts-of-global-ai-deployments-302795286.html
27. CNBC, “ON Semiconductor strikes $7 billion deal for Synaptics in physical AI push,” June 25, 2026. https://www.cnbc.com/2026/06/25/on-semi-synaptics-deal-physical-ai.html
28. AMD, “AMD Acquires MEXT to Advance Memory Optimization for Compute Infrastructure,” June 15, 2026; see also SiliconANGLE, June 15, 2026. https://www.amd.com/en/blogs/2026/amd-acquires-mext-for-memory-optimization.html
29. Tom's Hardware, “AMD takes over MEXT for memory tiering tech,” June 2026; Gartner DRAM/SSD price forecast cited in Network World, June 2026. https://www.networkworld.com/article/4186201/amd-acquires-mext-to-add-predictive-memory-optimization-to-its-ai-stack.html
30. CNBC, “Micron (MU) earnings report Q3 2026,” June 24, 2026; StockTitan, June 24, 2026. https://www.cnbc.com/2026/06/24/micron-mu-earnings-report-q3-2026.html
31. StockTitan, “Micron posts $41.5B Q3 revenue, guides Q4 to $50B,” June 24, 2026; Investing.com earnings call transcript, June 24, 2026. https://www.stocktitan.net/news/MU/micron-technology-inc-reports-record-results-for-the-third-quarter-6f50161e5zxh.html
32. IntuitionLabs, “Nvidia's $20B Groq Acquisition: Why It Paid 2.9x Valuation for LPU Tech,” 2026 (details the March 2026 Warren-Blumenthal antitrust letter). https://intuitionlabs.ai/articles/nvidia-groq-ai-inference-deal
33. Laura St. John, TechArena co-founder and advisor, from feedback shared with the author, July 2026. Quote is a proposed distillation pending her approval.
34. HPCwire, “Scaleway Acquires Qarnot to Add HPC Capabilities to European Cloud Platform,” July 10, 2026. https://www.hpcwire.com/off-the-wire/scaleway-acquires-qarnot-to-add-hpc-capabilities-to-european-cloud-platform/
35. Yahoo Finance / Business Wire, “Prefect Acquires Dagster, Uniting the Two Leading Modern Orchestrators,” July 13, 2026. https://finance.yahoo.com/technology/ai/articles/prefect-acquires-dagster-uniting-two-120000451.html
36. OpenAI, “OpenAI to acquire Ona,” June 11, 2026; see also CNBC, June 11, 2026. https://openai.com/index/openai-to-acquire-ona/
ZincFive’s Nickel-Zinc Answer to AI Power Spikes
As a proud media sponsor of the upcoming AI Infra Summit, TechArena is spending time this summer with companies up and down the AI stack to learn the latest on AI Infrastructure Requirements.
I had the pleasure of sitting down with Brandon Smith, ZincFive vice president of global sales and product, to discuss the rising power requirements for AI factories and the difference between traditional high performance computing (HPC) and AI workloads. Here's what we learned.
Q1: AI workloads don’t behave like traditional data center loads. They spike, collapse, and surge again in milliseconds. How has AI changed the shape of power demand inside the data center, and why do UPS architectures built for grid outages fall short of that new reality?
A: For decades we sized UPS systems around a single event: the loss of grid power. Battery selection, capacity planning, the whole architecture assumed a steady load broken only by a rare outage. AI ended that assumption. An AI workload can swing from idle to full draw and back in milliseconds, then repeat it thousands of times an hour. We call it AI Dynamic Power, and it has become the dominant profile inside modern data centers, not an edge case. A UPS designed to ride out a five-minute outage was never meant to absorb that kind of repeated, high-speed step load. Operators feel it as stress on the system and as headroom they paid for and cannot fully use. The demand did not just get bigger. It changed shape, and the power system has to change shape with it. The name of the game today is actually flexibility. Being able to adapt to current loads but also have flexibility in design to allow future expansion and support of next-gen GPUs and workloads, which are coming faster than ever.
Q2: The default response to that volatility has been to overbuild. Why is overbuilding a losing strategy as power density climbs, and what does it mean to move a UPS from passive backup to active stabilization?
A: The reflex has been to add battery, add headroom, stack another layer to soak up the volatility. This worked when GPU workloads were new and we were learning, but now that these systems are deployed and these workloads are better understood, it's time to optimize. Our industry research shows 84% of operators now rank total cost of ownership at the top of their priorities, and 57% need more power in a smaller footprint. Overbuilding pushes against both. Every redundant layer is capital, floor space, and cooling you pay for to cover a worst case a smarter system could handle on its own. The shift is functional. Power moves from passive backup to active stabilization. Rather than sitting idle until the grid fails, the system absorbs the spikes and releases energy as the workload calls for it, shaping load in real time before it travels through the facility and out to the grid. At that point the UPS is no longer only protecting the site. It is optimizing it.
Q3: You argue the advantage isn’t only architectural, it’s chemical. What makes nickel-zinc suited to the repeated, high-intensity pulses of AI in a way lead-acid and lithium-ion aren’t, and how does the BC2 AI put that to work?
A: The architecture matters, and the chemistry is what makes it possible. Nickel-zinc (NiZn) battery technology is built for high-power, rapid-response work. It takes repeated, high-intensity cycling without the fast degradation other chemistries show under that stress, which is exactly the pattern an AI load creates. Lead-acid is too heavy and too slow, and its life drops sharply under hard cycling. Lithium-ion brings a thermal runaway risk that makes you design around fire before you design around performance. Nickel-zinc runs on a non-flammable, water-based electrolyte, so that risk profile changes. We can site the system closer to critical equipment and remove layers of fire suppression and other costs that dramatically reduce total cost of ownership (TCO) and optimize the design for maximum GPU performance. The BC2 AI brings all of this into one cabinet. It intercepts transient load right at the UPS, absorbs the high-speed spikes, and recharges during the quiet intervals, so dynamic and flexible load management and backup runtime live in a single footprint instead of two separate systems, reducing the overbuild, improving TCO, and optimizing the design with a safe and flexible technology.
Q4: As racks push past 100 kW and space grows scarce, footprint and total cost of ownership now matter as much as raw performance. How does a high-power, compact chemistry change the math on space, cooling, and cost for an AI data center?
A: Space inside an AI data center is now a hard constraint. When a rack pulls more than 100 kilowatts, every square foot you give to backup power is a square foot taken from compute. A high-power chemistry changes that math. Nickel-zinc delivers more usable power per square foot, so you get the protection you need without oversizing the room around it. That runs straight into cost. A smaller footprint means less cooling load, simpler installation, and lower operating expense across the life of the system. The safety profile takes out cost too, since you are not wrapping the batteries in elaborate fire suppression. Add a longer service life and it becomes a total cost of ownership story, not only a performance one. The most efficient system is not the one with the most components. It is the one that delivers the performance, safety, and runtime you need with the least infrastructure built around it.
Q5: Beyond the data center walls, unmanaged load swings strain the grid and slow interconnection, already a years-long bottleneck. How does stabilizing demand at the source change a facility's relationship with the grid, and where does power infrastructure have to go next?
A: How a facility behaves at the fence line is starting to matter more than how it behaves inside. Large, unmanaged load swings do not stop at the wall. They reach the grid, and in power-constrained regions that affects stability and how fast a utility will clear new capacity. Interconnection queues already run for years and utilities understand that variable GPU-based workloads are a strain on their system and not a welcome addition to their aging infrastructure. A site that smooths its own demand internally reads as a better neighbor, and that can shape how much capacity gets allocated and how quickly a project breaks ground. That is where power infrastructure has to go next. It stops being a static box sized for a worst case and becomes a dynamic system that shapes demand at the source.

Solidigm Targets the Data Scientist Shortage with Luceta
Having established a strong position in the AI infrastructure conversation based on its solid-state storage solutions, Solidigm is now broadening that foundation, and its latest push may come as a surprise to those who haven’t been paying close attention. The company recently stepped into AI software with the launch of its Luceta AI Software Suite. On a recent episode of the Data Insights podcast, Jeniece Wnorowski and I spoke with A.J. Camber, VP and GM of AI software at Solidigm, about Luceta, which is designed to make computer vision AI accessible to industrial teams either without deep data science expertise or with an overloaded data science staff.
From Storage to Software
The path to the creation of an AI software business unit within a storage company reflects how much the AI landscape has shifted. A.J. previously spent two years running Solidigm’s strategy team, where Luceta began as an incubation project in an organization focused on long-term growth. In December, the company formalized the project as its own business unit based on the progress seen to date. Solidigm’s vantage point as a storage provider, particularly with its high-density quad-level cell (QLC) drives, gave the team a clear window into where data volumes were growing fastest: cameras.
“Cameras can generate terabytes of video, and that’s just with a single inspection point,” A.J. said. “Specifically as [industries] move into physical AI and other areas, we see computer vision really is the place for innovation right now.”
The Data Scientist Gap
A core premise behind Luceta is that the keenly felt shortage of data scientists is not going away. A.J. cited Bureau of Labor Statistics estimates suggesting that in 2026 demand for data science talent may be as many as ~11 million roles, while the number of people trained to fill those roles is only around one million. Compounding the problem, most existing data scientists are concentrated in about 20 large companies, leaving manufacturers, industrial operators, and others largely without access to this expertise.
Luceta is designed to close that gap by enabling domain experts, such as the line operators who know what a defect looks like, to build and iterate on AI models themselves. The platform automates technically demanding steps in the model-building process, including data diversification, the process of increasing the variety within a dataset to improve model performance.
A.J. estimated this step alone in the model building process would traditionally take a skilled data scientist working with a fairly large dataset roughly 20 hours per model. And a skilled data scientist has been required, because just adding more data blindly to a dataset can decrease model quality, make models slower, and make them more expensive to run. Now with Luceta, however, this step is automated by a data agent that automatically filters, groups, and annotates images, turning raw data into the needed labeled datasets.
“We aim to democratize and enable industrial engineers or mechanical engineers to do these sorts of things,” he said. “With our tool, we do that in the background for you.”
From Pilots to Production
The data quality challenge extends beyond simply having enough variety in a training set. A model that performs well under controlled circumstances often degrades when exposed to the variation and imperfection of an actual production environment, and that is where many AI initiatives stall. Traditional optical inspection systems are rigid by design, but AI-based approaches can adapt as conditions change, provided they are built on the right data and continuously refined.
A.J. noted that ongoing iteration with representative, real-world data is what separates projects that scale from those that never move beyond a pilot. Luceta is built to make that iteration accessible, steering users away from the shortcut of relying on pre-trained models that were not built for their specific environment or use case.
“We don’t think that our customers will be as successful as they can be if they’re just using pre-trained models,” A.J. said. “We want you to use your own data and to iterate on that tool so that not only is it tailored to your use case, but it builds trust with the people using it.”
Seeing It in Action
To demonstrate Luceta’s capabilities and ease of use, A.J. walked us through a live demo. The scenario was a packaging content inspection use case, the kind of application common in large retail or warehouse environments where the contents of a box must be verified before it ships.
Starting from a live camera stream pointed at a small collection of nuts and bolts, A.J. bookmarked a frame, annotated two objects, and allowed the platform to propagate those annotations across additional images automatically. From there, he configured an object detection profile, set a preference for minimizing false positives, and initiated model creation. Within moments, the model was running against the live feed, correctly identifying nuts and bolts with associated confidence scores, and appropriately returning no result when presented with an unrelated object.
The TechArena Take
Solidigm’s expansion into computer vision software may not be the expected move, but the reasoning behind it is sound. As physical AI and robotics move from research labs into warehouses, logistics facilities, and field operations, the demand for computer vision tools that can be trained quickly on real-world conditions is only going to grow. The enterprises best positioned to take advantage of that shift will be the ones that put capable tools in their employees hands to assist human judgment.
Luceta is a practical step in that direction, and for technology decision makers evaluating where AI investments can deliver measurable returns without long implementation cycles, it is worth a closer look. For more information, watch the full podcast, reach out to Solidigm’s industrial AI team at industrialaisw@solidigm.com, or visit solidigm.com.

RackRenew and AMI Turn Hyperscale E-Waste Into Enterprise Racks
IDC projects AI infrastructure spending will hit $487 billion in 2026, with annual spending on AI-optimized servers, storage, and networking expected to exceed $1 trillion by 2029.
As hyperscalers spend tens of billions on the newest compute generations, racks of perfectly serviceable equipment leave the same buildings by the truckload. Patrick Bliemer, global sales manager at RackRenew, joined me for a recent In the Arena episode to discuss how RackRenew gives used data center infrastructure a second life – fulfilling both a sustainability imperative and a business opportunity.
From Hyperscale Decommissioning to Remanufactured Racks
Patrick is a 30-year veteran of the high-tech industry, with most of his career in sales and management roles tied to the data center and PC markets. He took the role at RackRenew because of the unusual vantage point the company sits in. RackRenew is a global specialist in decommissioning and reverse logistics for hyperscale customers, giving the team a front-row seat to the volume of equipment leaving hyperscale floors. Seeing the sheer volume of equipment leaving hyperscale floors led to the question of whether there was a better way to reuse the equipment being decommissioned and offer it to the broader market.
And while the secondary market is full of refurbished IT gear, according to Patrick no other company recommissions Open Compute Project (OCP) racks coming off the floors of the world’s largest cloud operators.
Embodied Carbon and Second Life Racks
Patrick pointed to recent industry analysis suggesting that an additional two to five million tons of e-waste will hit the market by 2030 as the AI build-out accelerates. Contrary to the airy connotations of the word cloud, he noted, “over 70% of the cloud is made up by iron and plastic.” Manufacturing all of those servers, racks, and chassis takes water, electricity, and raw materials, generating a heavy embodied-carbon footprint long before any workload runs. When RackRenew remanufactures an OCP rack, that carbon has already been written off, so customers buy at either zero embedded carbon or, when new components are swapped in, very low embodied carbon. With public concern about data center power and water use rising, Patrick argued, proving the industry is responsibly adding capacity is no longer optional.
For an AI-era buyer, time is the more visceral selling point. While lead times for new systems can stretch between 6 and 12 months, RackRenew aims to deliver products within weeks rather than months.
Why AMI Matters
It turns out that rejigging hardware was the easy part. Every OCP component carries a baseboard management controller (BMC) chip running OpenBMC, and hyperscalers heavily customize that firmware before equipment is decommissioned. To prevent reuse, Sims Lifecycle Services destroys these chips. “We grind up the BMC chips entirely,” Patrick said, “it goes to dust, literal dust.”
That leaves a remanufactured server with a clean chassis, validated components, and no nervous system. RackRenew rebuilt the management stack on an open foundation with AMI, which is developing a generic open-standards BMC for the RackRenew portfolio and can build bespoke feature sets on demand. Patrick credits the partnership with restoring secure boot and root of trust together with the original equipment manufacturers (OEMs), and with giving a roughly two-year-old company unexpected credibility among very large prospects.
Limits to a Circular Cloud
Patrick is candid about the limits of the model. Some decommissioned gear is already past end-of-life at the CPU level, where firmware updates alone cannot fully restore the security posture. On integration, he said, “I don’t think honestly that a seamless integration exists.” His framing is workload fit. Agentic AI use cases need leading-edge silicon, but plenty of enterprise tasks, including virtual private servers, Kubernetes, and email servers, do not.
On the criticism that open ecosystems drive up total cost of ownership, Patrick is unmoved. “Over the long run, open standards will always drive faster innovation and will always lead to lower cost,” he said.
RackRenew already ships compute nodes, compute servers, and storage solutions, with AI GPU servers planned next. The volume poised to leave hyperscale floors over the next three to five years, Patrick believes, makes the case for itself. “It will be a crime to see that go to the waste pile,” he said.
TechArena Take
RackRenew is built to address the additional two to five million tons of e-waste projected to hit the market by 2030. The company remanufactures decommissioned OCP equipment and returns it to market at near-zero embodied carbon, pairing that sustainable approach with a speed advantage that sidesteps the component shortages slowing traditional. Their partnership with AMI has helped in delivering an open-standards BMC that restores full manageability and re-establishes a root of trust to make the gear enterprise ready. As AI continues to drive unprecedented demand for compute, the infrastructure conversation has to include not just what gets deployed, but what it takes to give a longer life to what is already on the ground.
Watch the full episode on TechArena.


DigitalOcean and Solidigm Unpack AI Storage Density and Speed
DigitalOcean's Dan Brown and Solidigm's Ty MacAdam join Data Insights to unpack how storage infrastructure — not just GPUs — drives real AI performance, covering data velocity, cluster density, and DigitalOcean's new Inference Router.



Enter Our Pre-AI Infra Summit Top Innovators Contest
When we announced our media partnership with the AI Infra Summit earlier this year, we said we’d be spotlighting the innovations driving the field forward. Our event coverage has already begun, and today we’re putting that work into action in a new way: with the inaugural TechArena Ad Astra AI Infrastructure Competition.
The contest is an open call for companies attending the AI Infra Summit to make their case for why their technology belongs on the shortlist of this year’s most significant innovations in AI infrastructure. One winner and three honorable mentions will be selected by a panel of TechArena Advisors and will be featured on our Ad Astra Showcase page.
The winning company also receives a suite of content opportunities to amplify their story before, during, and after the summit in Santa Clara this September, including the following assets:
- 5 Fast Facts Interview Blog: A Q&A published on the TechArena Forum focused on AI infrastructure requirements with select answers featured in TechArena's 2026 AI Infrastructure Requirements Report
- Solution Brief: A two-page digital solution brief developed by TechArena for the winning company to use during and after the event
- Recap Blog Mention: A mention of the winning company’s innovations in TechArena’s recap blog published during the event
- Post-event Key Insights Blog: A contributed blog by the winning company published on the TechArena platform capturing the company’s key insights from the show
Submissions are judged on three criteria:
- Alignment to one of the summit's focus areas (Compute, AI Data Center, Data Movement, Data & Models, or Physical AI)
- Evidence of real-world impact backed by measurable outcomes
- Clarity of communication
Entries are 200 words. The contest is open now through July 22 at 5 PM PDT, and is open to any company with at least one employee attending the AI Infra Summit in person.
If your company is doing work worth talking about, this is the place to say so. Submit your entry here.
Free Tickets and Discounts from TechArena
If you haven’t yet registered for the AI Infra Summit, now is the time to act! As part of our partnership, we’re pleased to offer benefits to our TechArena followers who want to join the conversation in Santa Clara this fall:
Free expo tickets (valued at $447) are available to qualified individuals working within the AI infrastructure field. Apply for free expo tickets.
A registration discount is available for full access and VIP tickets. Quote TECHARENA15 on the registration page to save 15%.