
.webp)
Subscribe to Our Newsletter
Read the latest in the world of AI, data center, and edge innovation.
As the AI PC market moves from hype to real deployment, MLCommons has released a critical piece of infrastructure: MLPerf Client v1.0, the first benchmark specifically designed to measure the performance of large language models (LLMs) on PCs and client-class systems.
The release marks a major milestone in the effort to bring standardized, transparent AI performance metrics to the fast-emerging AI PC market, ML Commons officials said.
It’s a move that couldn’t be more timely. From developers building AI-first applications to enterprises deploying productivity tools powered by on-device inference, there’s a growing need for standardized, vendor-neutral performance metrics that reflect real-world usage. MLPerf Client v1.0 delivers just that.
MLPerf Client v1.0 introduces a broader and deeper evaluation suite than its predecessor. Here’s what stands out.
Expanded LLM support:
New prompt categories:
Wider hardware support:
Benchmarking made easy:
With participation from AMD, Intel, Microsoft, NVIDIA, Qualcomm, and top PC OEMs, this version represents one of the broadest industry collaborations yet in the AI PC space.
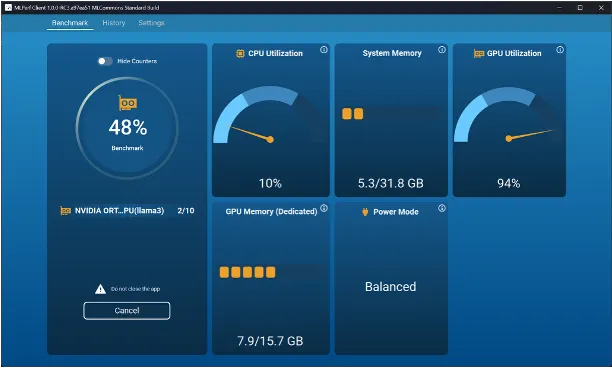
The AI PC conversation just got real. MLPerf Client v1.0 gives the industry a common language to talk about performance—not just raw inference speed, but usability across context lengths, structured prompts, and compute environments that look more like real end-user conditions.
It’s especially important in an ecosystem full of proprietary benchmarks and marketing-led performance claims. For OEMs and chipmakers racing to stake out territory in the AI PC era, this is a reality check.
But the bigger picture is this: AI workloads are going local. And that means we need tools that reflect how AI is actually used on devices with power, memory, and thermal constraints. MLPerf Client v1.0 answers that call with open, standardized, and scriptable benchmarks—all the ingredients needed to build trust across the ecosystem.
As AI PC adoption ramps, expect MLPerf Client to play a foundational role—not just in performance reviews, but in how next-gen silicon, SDKs, and even software experiences are shaped.
Download MLPerf Client v1.0: mlcommons.org/benchmarks/client.
